平台简介
FlagEval (天秤)大模型评测体系及开放平台,旨在建立科学、公正、开放的评测基准、方法、工具集,协助研究人员全方位评估基础模型及训练算法的性能,同时探索利用AI方法实现对主观评测的辅助,大幅提升评测的效率和客观性。FlagEval (天秤)创新构建了“能力-任务-指标”三维评测框架,细粒度刻画基础模型的认知能力边界,可视化呈现评测结果。
目前已推出语言大模型评测、多语言文图大模型评测及文图生成评测等工具,并对广泛的语言基础模型、跨模态基础模型实现了评测。后续将全面覆盖基础模型、预训练算法、微调/压缩算法等三大评测对象,包括自然语言处理(NLP)、计算机视觉(CV)、音频(Audio)及多模态(Multimodal)等四大评测场景和丰富的下游任务。
FlagEval 是智源FlagOpen大模型开源技术体系的重要组成部分。FlagOpen 旨在打造全面支撑大模型技术发展的开源算法体系和一站式基础软件平台,支持协同创新和开放竞争,共建共享大模型时代的“Linux”开源开放生态。
以下为2024年9月截取的图片,模型排名可能随着日期不同而不同,截图仅供参考,具体以网站内为准:
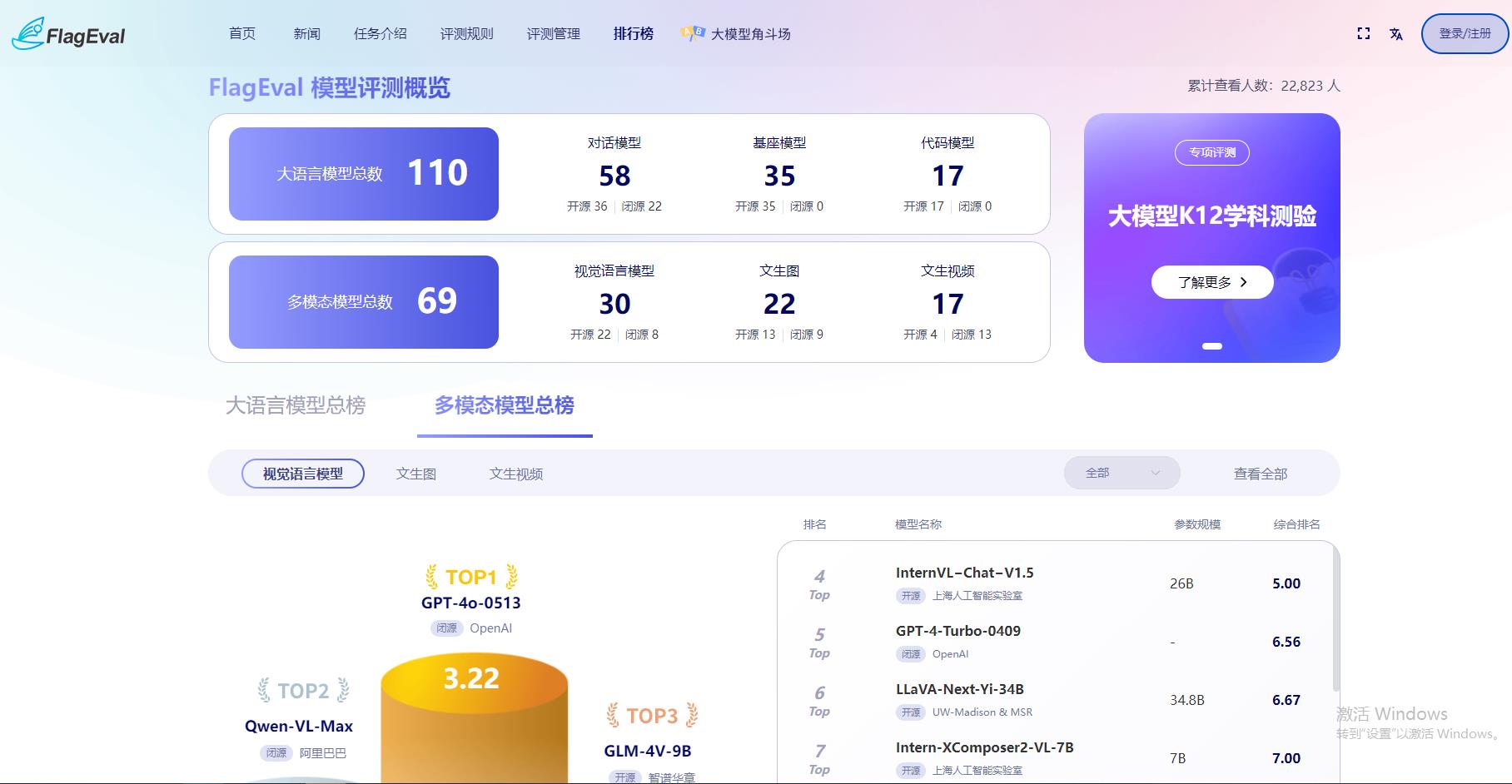
相关导航



暂无评论...