AGI-Eval评测社区,AI大模型评测社区
AGI-Eval是一个AI大模型评测社区
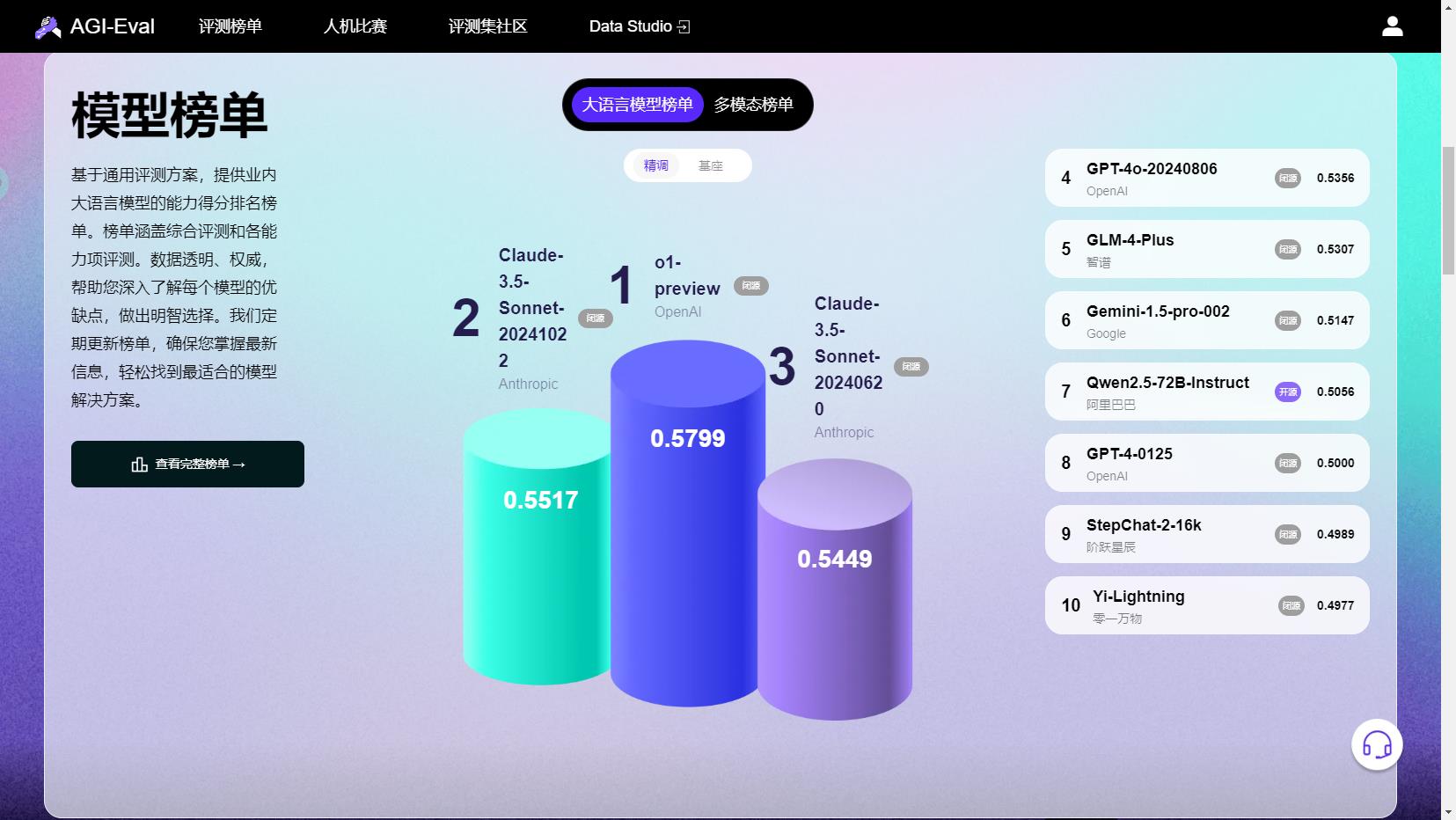
里面有AI大模型评测榜单、人机比赛、评测集社区、Data Studio这几个板块
Hugging Face 推出新版开源大模型排行榜(Open LLM Leaderboard)
评测榜单旨在为大语言模型和多模态模型提供全面、客观且中立的得分与排名,同时提供多能力维度的评分参考,以便用户能够更全面地了解大模型的能力水平。
FlagEval (天秤)大模型评测体系及开放平台,旨在建立科学、公正、开放的评测基准、方法、工具集,协助研究人员全方位评估基础模型及训练算法的性能,同时探索利用AI方法实现对主观评测的辅助,大幅提升评测的效率和客观性。
SuperBench是由清华大学基础模型研究中心联合中关村实验室在2024年共同发布的大模型综合能力评测榜单
LiveBench 是一个针对大型语言模型(LLM)的权威基准测试平台,提供一个公平、客观且无污染的评测环境,以评估和比较不同 LLM 的性能
Artificial Analysis平台是一家领先的独立AI基准测试和分析平台