随着GPT-4V多模态模型的发布,具备图像识别的大语言模型,正在成为未来的趋势。
近日,KAUST 团队以及来自 Meta 的研究者宣布,他们将 MiniGPT-4 重磅升级到了 MiniGPT-v2 版本。
论文地址:https://arxiv.org/pdf/2310.09478.pdf
论文主页:https://minigpt-v2.github.io/
Demo: https://minigpt-v2.github.io/
代码:https://github.com/Vision-CAIR/MiniGPT-4
具体而言,MiniGPT-v2 可以作为一个统一的接口来更好地处理各种视觉 – 语言任务。同时,本文建议在训练模型时对不同的任务使用唯一的识别符号,这些识别符号有利于模型轻松的区分每个任务指令,并提高每个任务模型的学习效率。
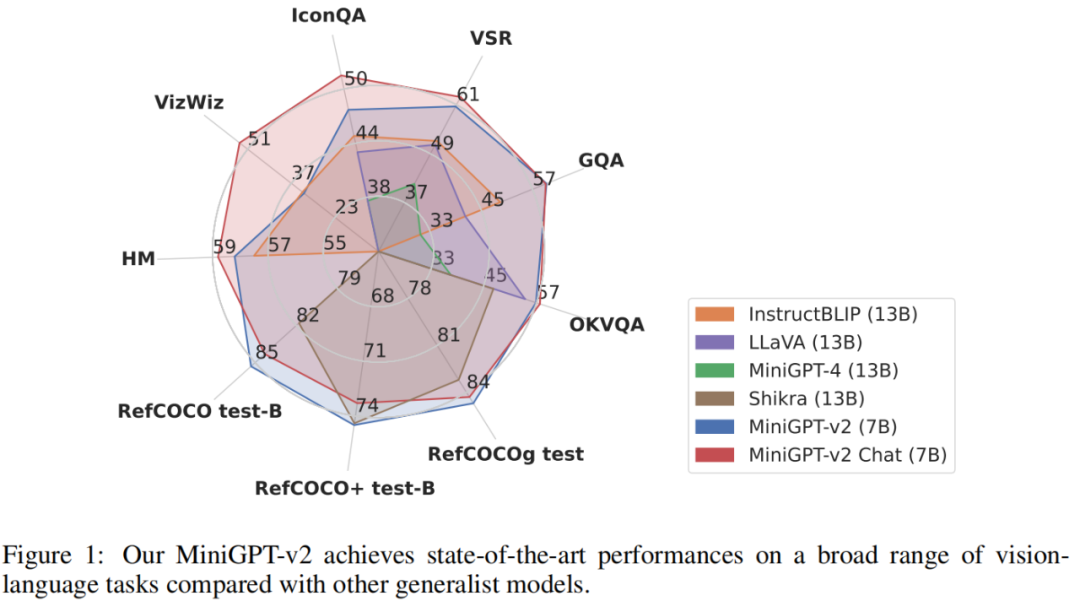
为了评估 MiniGPT-v2 模型的性能,研究者对不同的视觉 – 语言任务进行了广泛的实验。结果表明,与之前的视觉 – 语言通用模型(例如 MiniGPT-4、InstructBLIP、 LLaVA 和 Shikra)相比,MiniGPT-v2 在各种基准上实现了 SOTA 或相当的性能。例如 MiniGPT-v2 在 VSR 基准上比 MiniGPT-4 高出 21.3%,比 InstructBLIP 高出 11.3%,比 LLaVA 高出 11.7%。

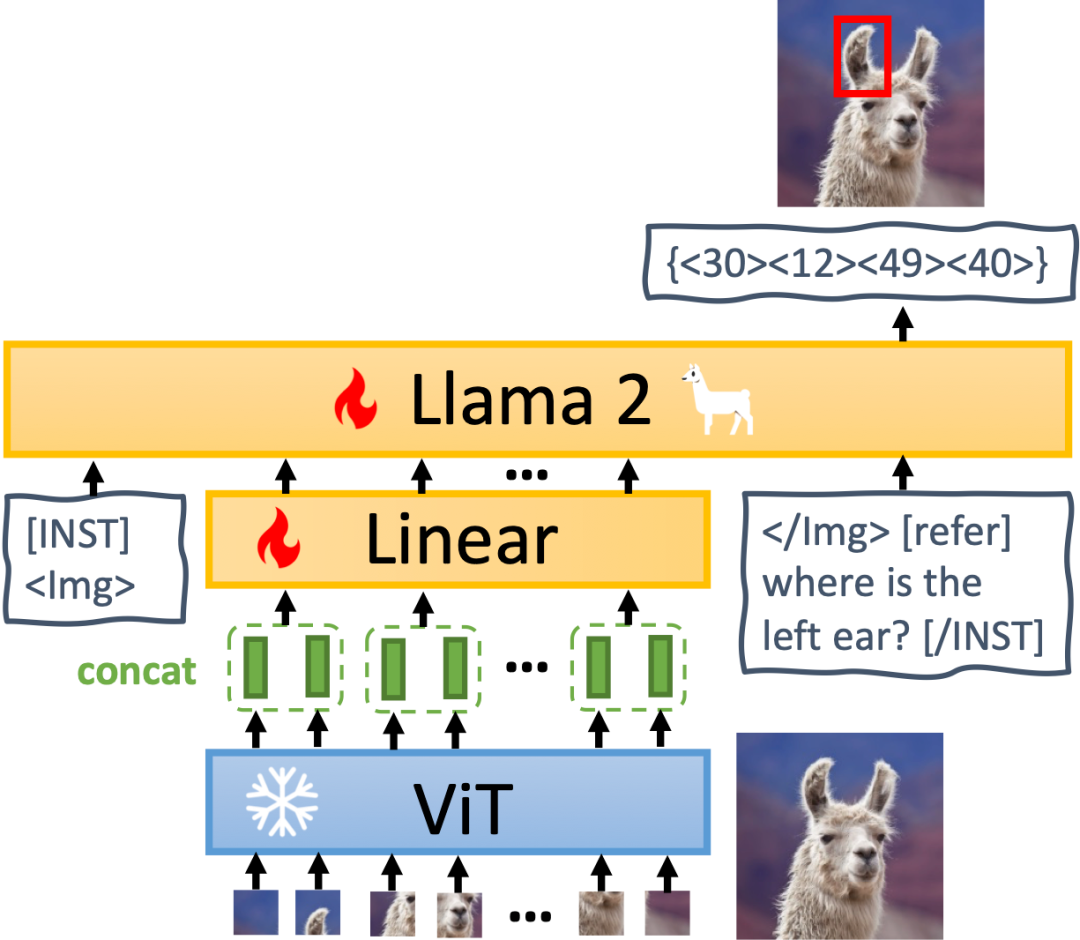
MiniGPT-v2 模型架构如下图所示,它由三个部分组成:视觉主干、线性投影层和大型语言模型。
视觉主干:MiniGPT-v2 采用 EVA 作为主干模型,并且在训练期间会冻结视觉主干。训练模型的图像分辨率为 448×448 ,并插入位置编码来扩展更高的图像分辨率。
线性投影层:本文旨在将所有的视觉 token 从冻结的视觉主干投影到语言模型空间中。然而,对于更高分辨率的图像(例如 448×448),投影所有的图像 token 会导致非常长的序列输入(例如 1024 个 token),显着降低了训练和推理效率。因此,本文简单地将嵌入空间中相邻的 4 个视觉 token 连接起来,并将它们一起投影到大型语言模型的同一特征空间中的单个嵌入中,从而将视觉输入 token 的数量减少了 4 倍。
大型语言模型:MiniGPT-v2 采用开源的 LLaMA2-chat (7B) 作为语言模型主干。在该研究中,语言模型被视为各种视觉语言输入的统一接口。本文直接借助 LLaMA-2 语言 token 来执行各种视觉语言任务。对于需要生成空间位置的视觉基础任务,本文直接要求语言模型生成边界框的文本表示以表示其空间位置。
Mini-GPT不但可以识别图中的物体,还能标注不同物体所在的区域。
目前,Mini-GPT已经提供了免费的Demo。